Around this time last year, I wrote a thesis piece to lay out how capital and innovation cycles work especially in the context of big technological unlocks like the one we are seeing play out in AI. One of the central points I was making in the piece was around how CAPEX and OPEX cycles intersect and how value pools shift over time. A crude analogy would be if there were a gold rush, would you rather invest in one of the many companies digging for gold hoping they’d strike, well, gold, or invest in a company trying to dominate the picks & shovels market. Perhaps a less crude analogy — no pun intended — would be around oil. In the first few decades of formalisation of oil exploration, you’d be better off investing in the ‘extractive’ part of the industry; i.e. businesses that help extract this resource. However, if you invested in the OnG index in the 1990s, you’d be sitting on a flattish return even though the price of oil has only gone up, because the world moved on to the distributive part of the oil business — e.g. companies that take this droplet of oil and build cars, heavy machines, or other derivative products with it. It is important for founders & investors to think about where value pools lie today and where they may shift tomorrow as the underlying core technology reaches commodification. I ended the piece with a claim that we were still in the extractive phase of AI; that AI tokens are the new droplets of oil, and companies that help extract this resource better, faster, cheaper, are the ones that will accrue value first. This piece will pick up where we left off and explore these ideas further.
So, are we reaching diminishing returns on the extractive phase of AI already? How far are we into the distributive phase? Do winners in both phases look the same? More importantly, do founders who win these transitions look the same? To understand some of these, we’ll go back to the car company analogy we set up in the prior blog. All images are hand drawn and not to scale for simplicity. If you want to see the original sources, I cite them at the bottom.
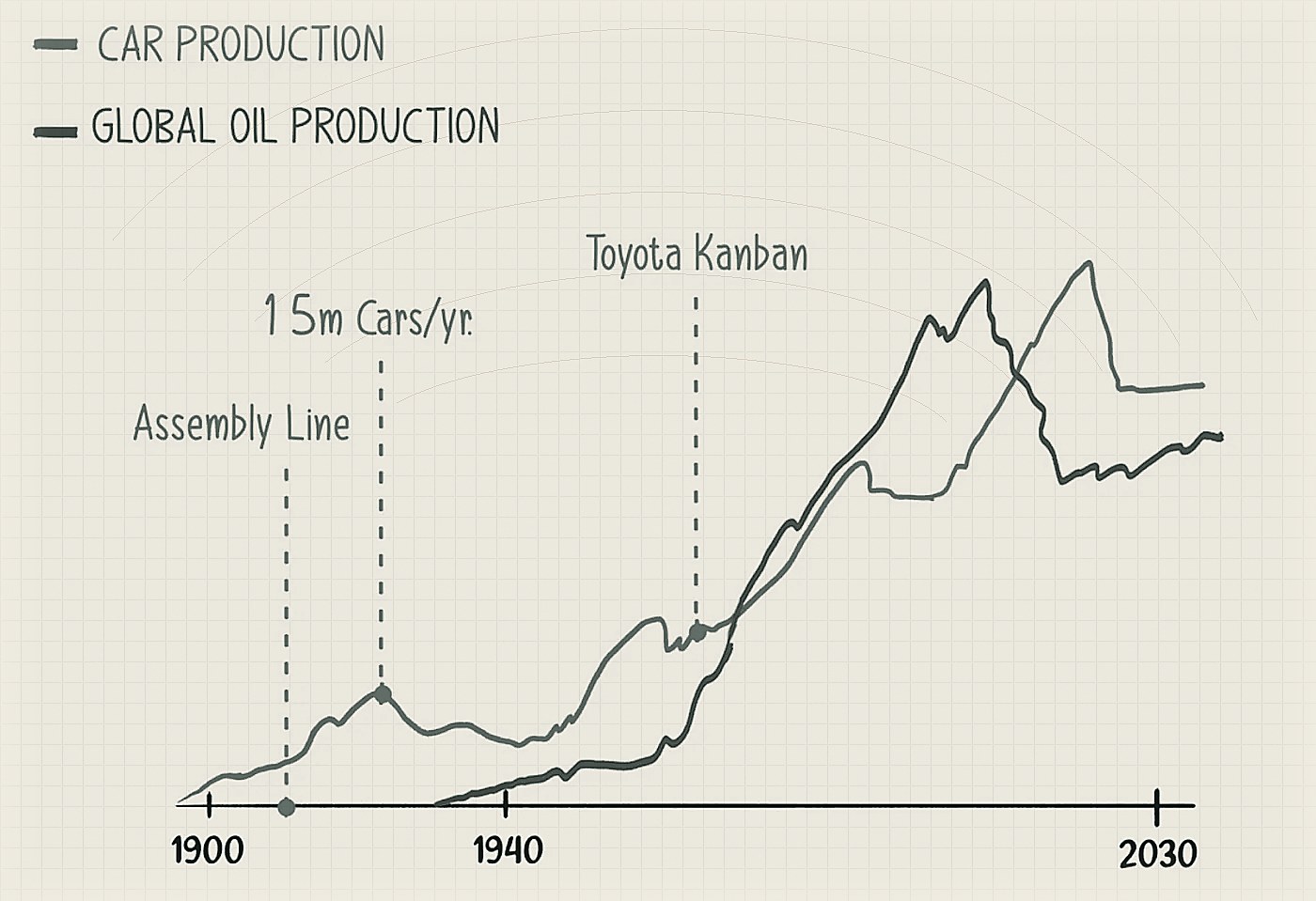
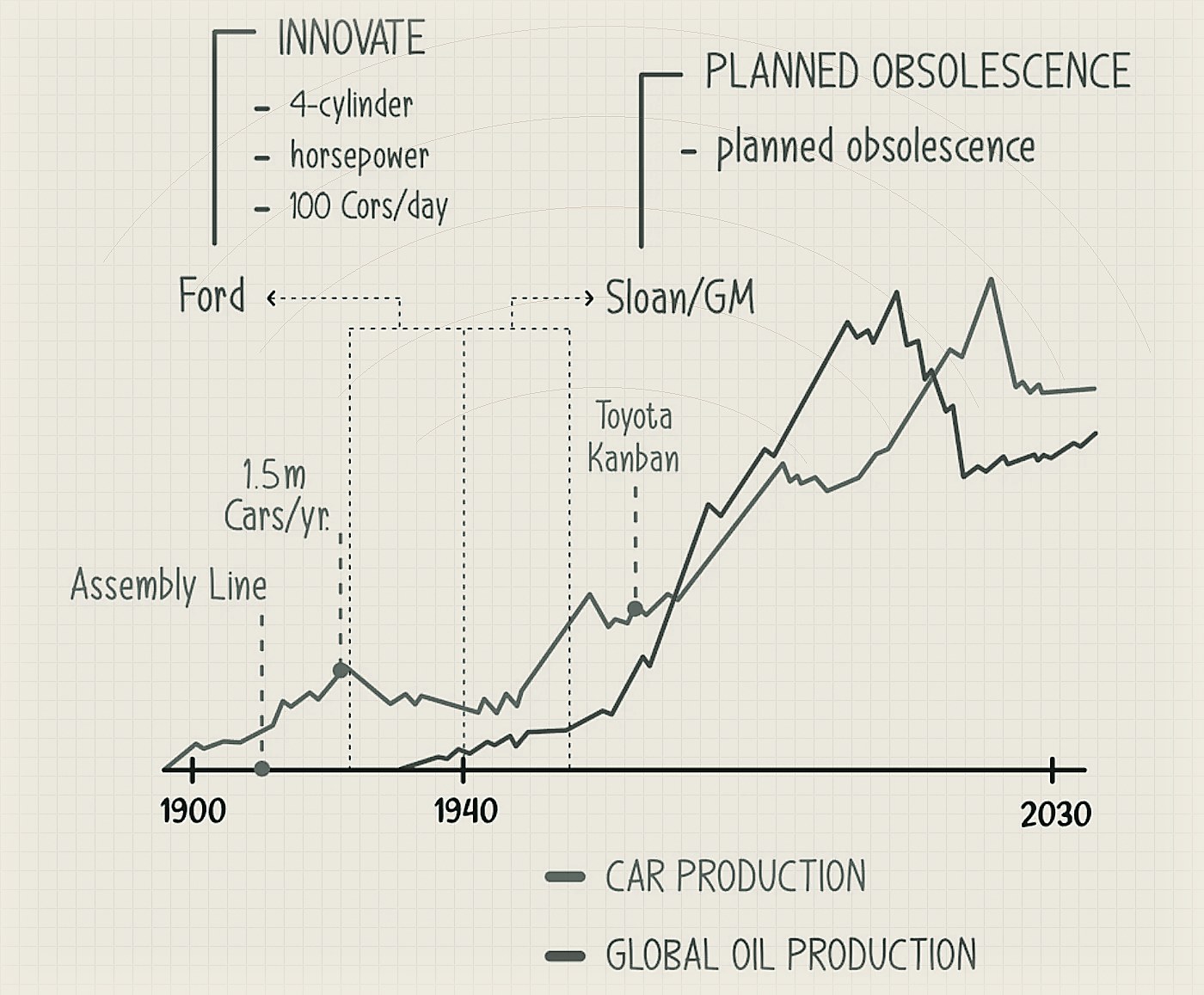
By the turn of the last century, we were formalising oil production in the US. We had been digging for oil for a 100+ years by then, but only in the early 1900s did we figure out how to scientifically explore and extract oil with precision & predictability. Oil production really took off in the 1930s but even before that, pioneers like Ford had understood the power of this new resource. Ford introduced assembly line production in 1914 and by the time the US hit a recession in the late 1920s, Ford had already sold 15M Model Ts, peaking at 1.5–2M cars / year. While Ford wasn’t in the ‘extractive’ business — they weren’t digging for oil per se — they were very closely partnered with the oil companies of the time. Oil companies saw automobiles as the first “mass use-case” for oil and they standardised refined gasoline to Ford’s specifications. The earliest fuel stations were built in Pittsburgh & LA which were also places with highest Ford sales driven by either proximity to Detroit where Ford was HQ’ed or weather- and wealth-related reasons in the case of California. By the mid-1920s, Ford had ~60% of the automobile market — so high that they barely needed to advertise.
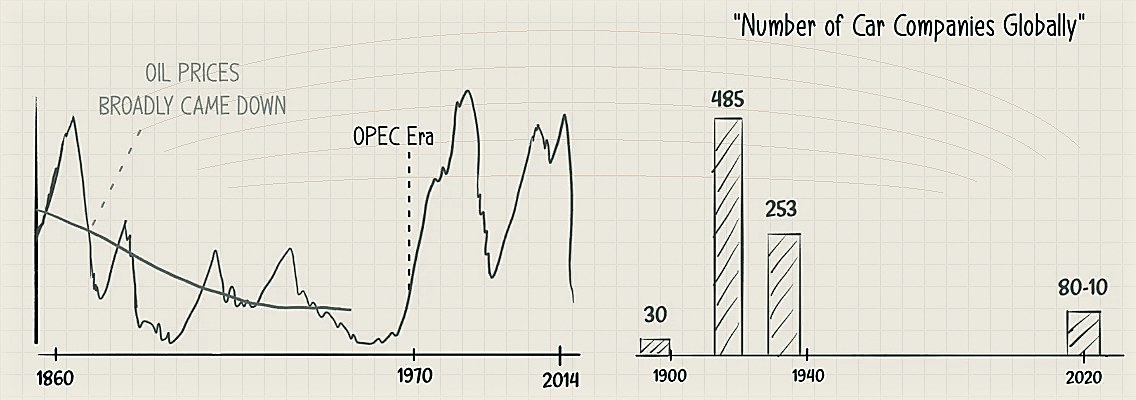
Meanwhile, barring shocks from wars (US civil war, WW1 & 2), the oil prices per barrel were generally coming down until OPEC was founded in the 1960s to artificially control the price and production. The oil industry was clearly entering its ‘distributive phase’. More and more car companies were coming out of the woodworks. At its peak, the world had ~500 car companies globally, a majority in the US. A relatively smaller US player — GM — was picking up under the leadership of Alfred P Sloan, and things were about to get interesting.
Sloan saw that by the late 1920s, the market for new car sales was saturating. People wanted more colour, more designs, more style, not just more engine, or more horsepower. Henry Ford was a classic “extractive” phase founder — innovation driven, engineer at heart, obsessed about perfecting the next engine, perfecting the production line. Ford had discovered that black paint dried the most quickly on his assembly lines and famously said “any customer can have a car painted any colour that he wants so long as it is black.”
Clearly, Ford wasn’t going to be the one to ask what the customer wanted — to him they all would say “faster horses”. Sloan, on the other hand, was a classic “distributive phase” founder. This phase needed a marketing-driven approach that Ford wasn’t great at but Sloan was.
Sloan designed a marketing tagline around “planned obsolescence” — twice every year, he’d campaign car owners to discard their perfectly well-running cars and opt for a newer, more stylish, more in-vogue car. Built, of course, by GM. Over the next 20 years, GM hit ~40% of market share in the US and Ford went to 20% down from 60%.
So what can we learn from how the automobile industry evolved?
- Early part of the innovation cycles centred around a core “mega resource” (electricity, oil, etc) favours extractive businesses that help mine that resource.
- As the underlying atomic resource gets commoditized (oil droplet, cpu-cycle, AI-token), competition centres on efficiency and scale rather than product uniqueness. Often the largest and most efficient companies attract the most capital, and eventually survive.
- Founders dominating the extractive phase need to keep reinventing and understand shifting consumer behaviours — even when these behaviours are enabled by the very resources they are helping unlock. As the cycles shift to distributive from extractive, many founders will find this shift jarring.
History doesn’t repeat itself but it often rhymes. How does all this tie back to AI? Over the last 1yr, a lot has happened.
Extractive phase in AI continues
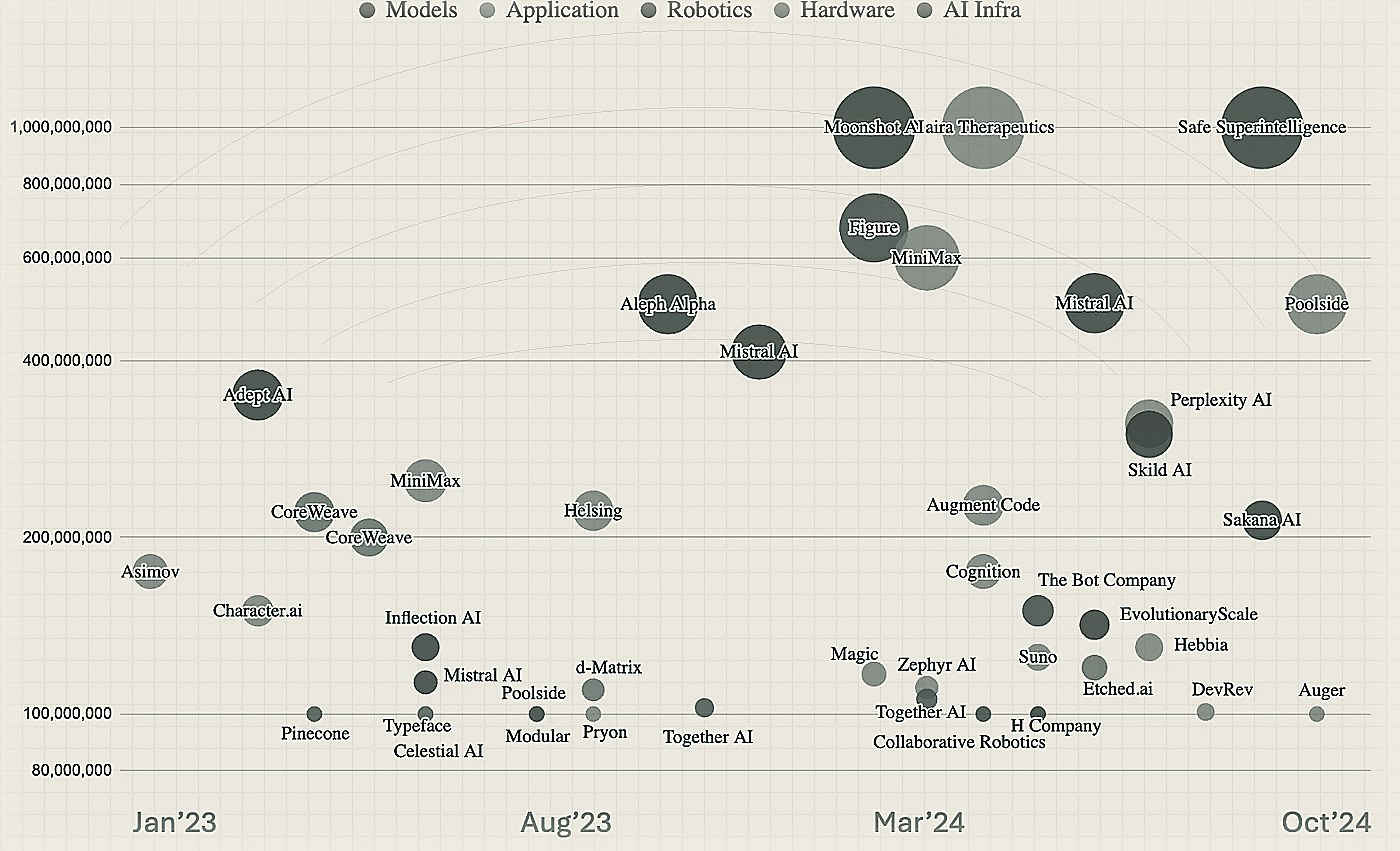
Companies that are part of the extractive cycle of AI — the silicon companies, the LLM companies, the data companies — have reaped a lot of the benefits. Large market-cap companies like Google, Meta, AMD, Nvidia that are either part of the foundation model or silicon ecosystems have added several trillion dollars of market-cap in 2023–24. Nvidia’s ascent has been the fastest. It went from $2 trillion to $3 trillion in a record 96 calendar days. Microsoft took 649 days to do so, while Apple took 718 days. In the private markets too, a lot of large financings have happened closer to the extractive part of this cycle although there is a ton of growing excitement on the application side as well and the emerging view is that transformer-like architectures are reaching an efficiency asymptote.
We may be reaching commoditization of the lower layers in AI
The AI opportunity set is bi-modal and will likely remain so for the foreseeable future. Quite simultaneously there is an ongoing AI Glut as well as an AI Crunch. Categories that were wide open a year ago have now been absorbed into the model layer. Things that were hard to build a year ago, are now an API call away. On the one hand, several companies with negligible revenue are raising massive rounds, and on the other hand, several fast growing companies aren’t able to raise capital because of high churn, low defensibility, or high valuations set in their prior rounds. While the absolute dollars going into AI has gone up from 2023, there is a clear flight towards large to very large financings and serA & B feel much tougher in AI today than a year ago. The below charts summarise this well (ref: stateofai report).
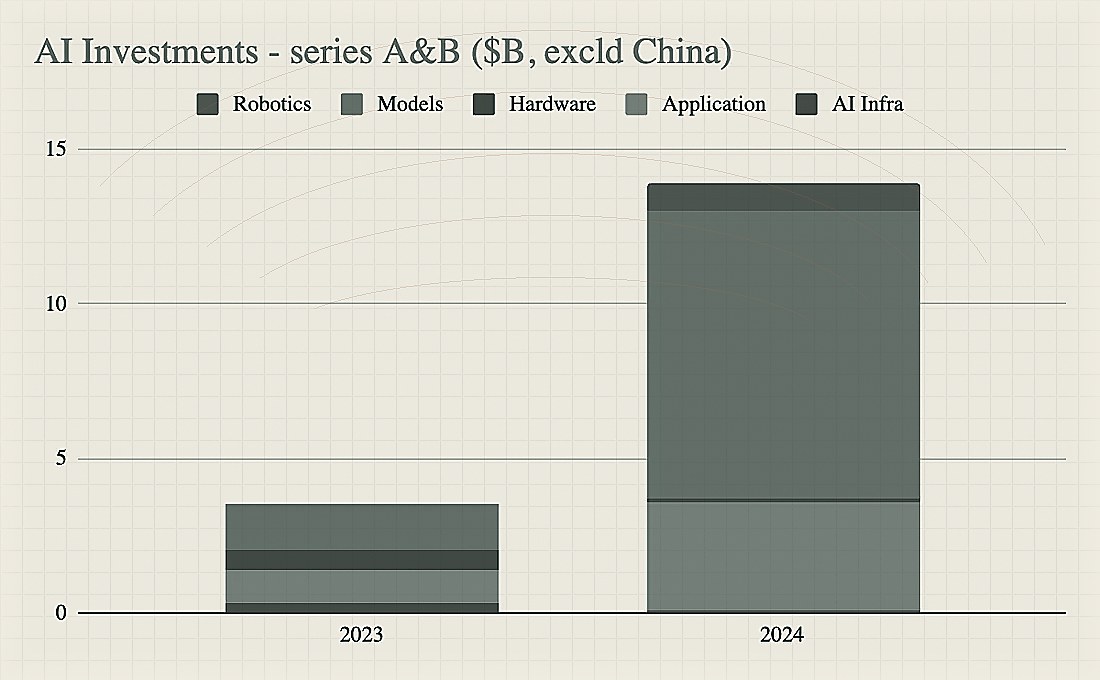
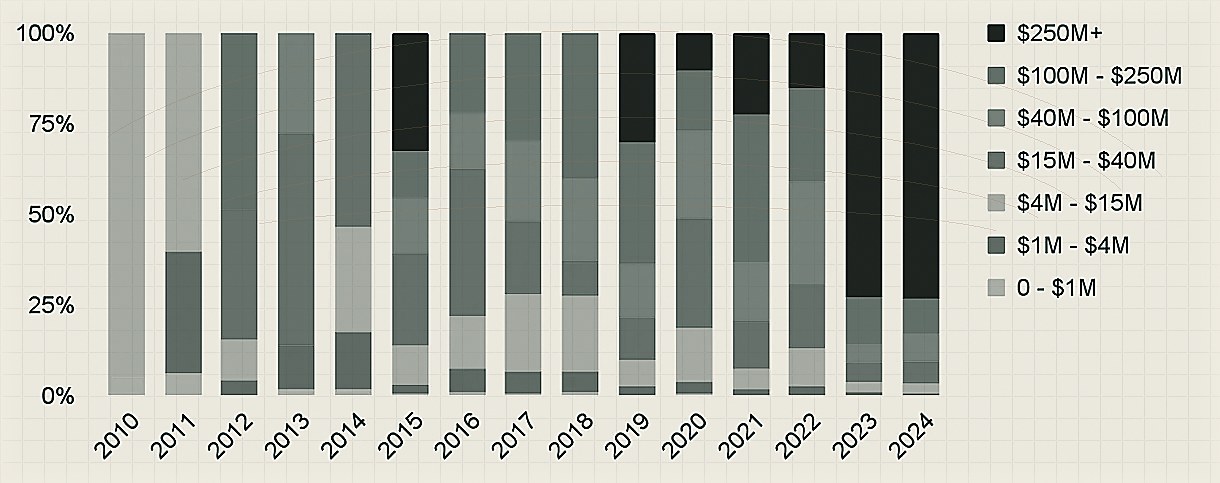
Beyond a certain point, it’s hard to differentiate one AI-generated image from another when both are practically indistinguishable from a real image. Capital is agglomerating behind those already big — signals of commodification — or those who are building de-novo algorithmic approaches in the model layer (e.g. Cartesia for Audio, or Evolutionary Scale for Bio, or SkillD for robotics). Satya Nadella pretty much said this during the Oct’24 quarterly earnings call — “capital outlay for AI training is rate-limited by monetization of inference” — most likely meaning that there is no reason to get into the model arms race unless the inference side of the market scales to justify further capex. Beyond these, dollars are moving to the layers above — agents, applications, solutions, services.
Several extractive founders leaving, indicating we may be entering early stages of the distributive phase in AI
The “Ford vs Sloan” of this cycle is also playing out. OpenAI lost most of their founding team and my guess is that they are struggling to make the shift from a R&D focused company to a commercialization-heavy company — something I saw happen at Google[x] circa 2014–17. CTO @ FigureAI left to start PersonaAI. Inflection, Adept, H Company, and several others have had founders leaving after raising 100M+. Innovation is messy. Commercialization is messy. This is a feature, not a bug. Not every founder is going to enjoy or excel at this transition.
All that said, there is some real value being created & realised in AI. MSFT for example has already realised 10B+ of value through their AI products in 2024 — the fastest ramp in their history for any product. But it’s not easy to understand what are the enduring spaces in AI that are defensible against incumbents or adjacent players. In many ways, investing in AI is a bit of a bar-bell today. To the extreme left are categories such as data centres, accelerators / GPUs and energy and to the right are consulting firms. Both of them are easier to parse and invest behind. Everything in the middle is up for grabs and that’s where all the confusion and chaos is, and also the opportunity.
Frameworks for the future of AI
Here’s a framework to evaluate opportunities and risks in AI in the coming years. It’s a multi-dimensional framework which I’ve reduced to just a few dimensions for now. On the y-axis is # of people gainfully employed doing a task, on x-axis is how complex / creative that task is — the more complex, or the more creativity it needs to be done well, the fewer the people exist in the world who can perform that task. The less likely it’ll be fully displaced by AI. Designing a new mathematical theory or discovering a new law of physics is probably at the far end of that spectrum but doing basic copy-writing, artwork, simple reasoning, etc, all likely lie in the blue or green segments. Either they’ll be fully displaced (i.e. those roles will no longer exist on Linkedin in 5–10yrs), or reduce in volume/relative salary due to a co-pilot increasingly eating into the role. Similarly, the z-axis: the more bespoke / non-repetitive a task is, the harder it is for AI to perform it well.
With this framing, it isn’t too hard to realise that 80% of the jobs humans perform in the knowledge economy will have at least 20% of their jobs done by AI. And 20% of these jobs will likely be completely taken away by AI. It’s already started to happen in some categories — 25% of code Google has shipped lately is AI-generated, Klarna is looking to cut its workforce by 50% using AI. Below is a bit of napkin analysis on how this might play out for two categories just to make the framework easier to understand.
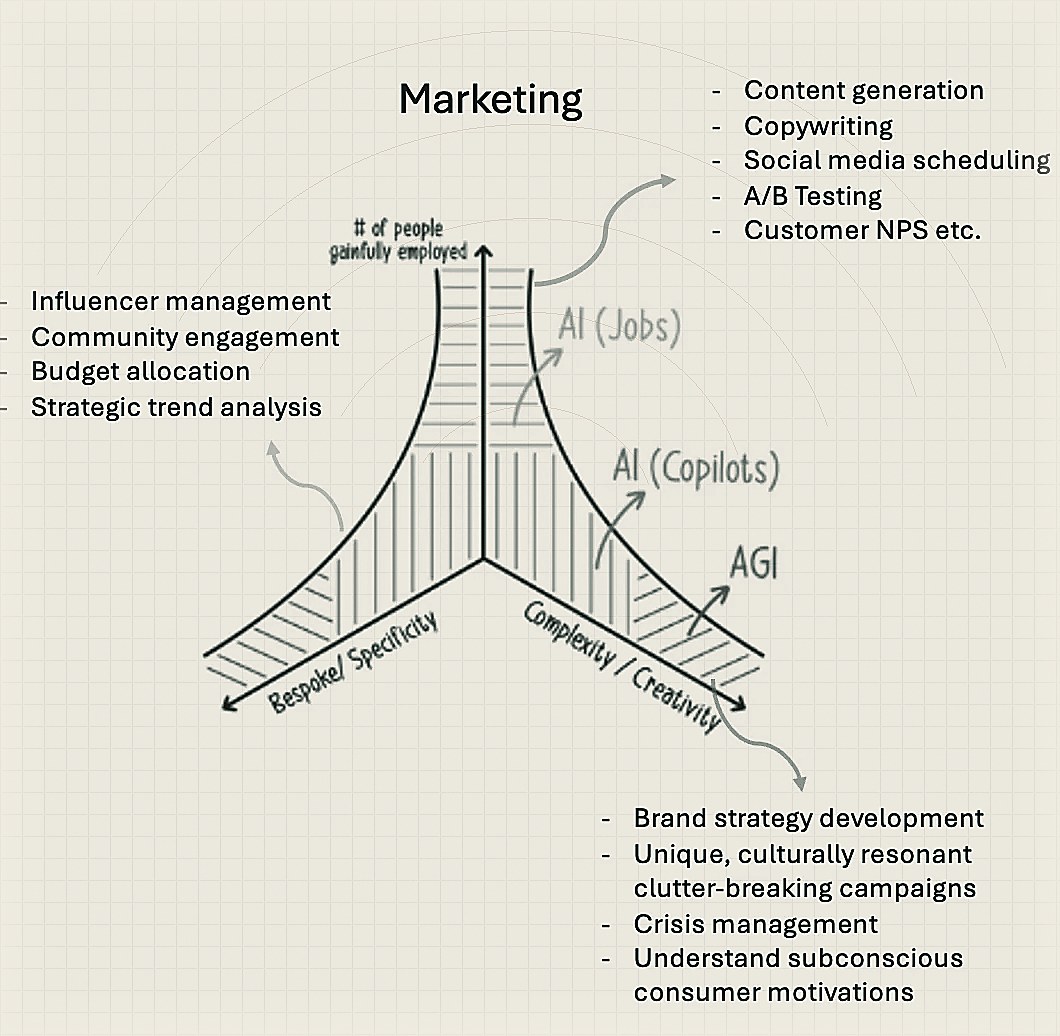
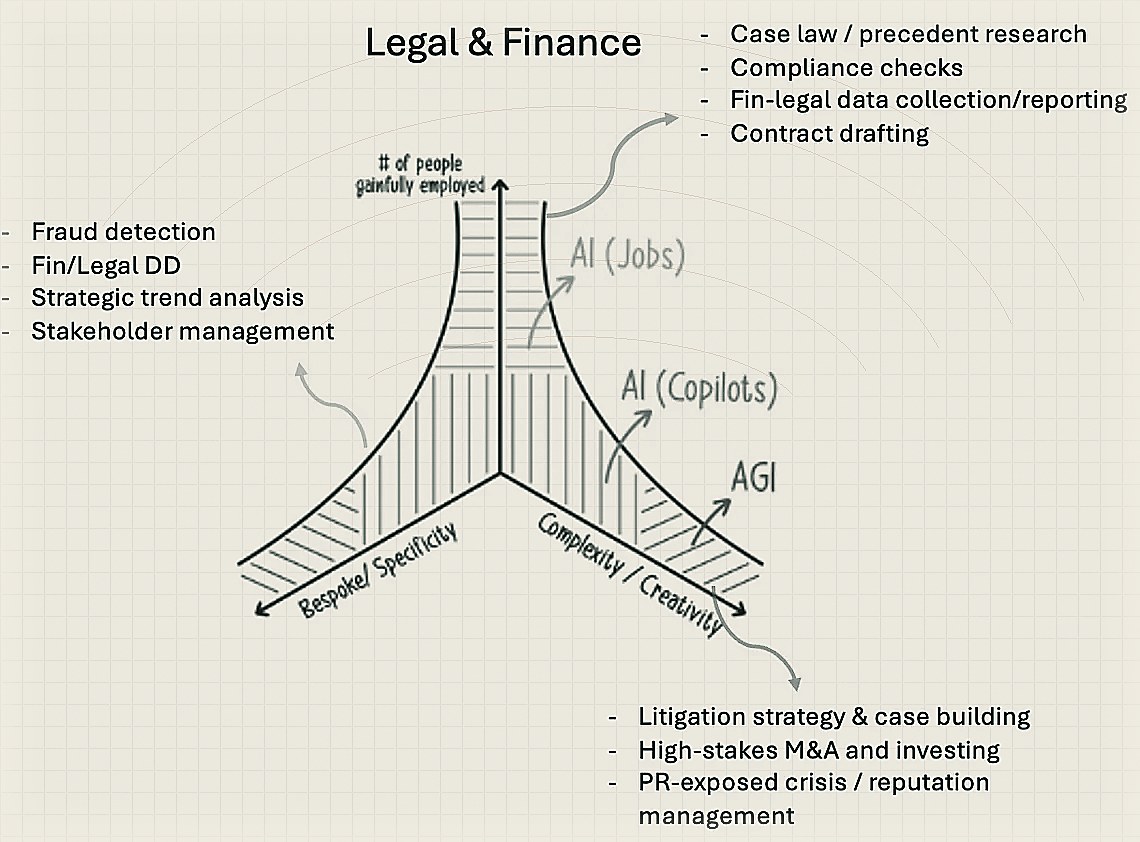
I’ll leave you all with perhaps 3 final thoughts in terms of what I find interesting to mull over and why some of the largest categories are ready and prime to get supplanted.
1. Decoupling of Workflows & systems of records
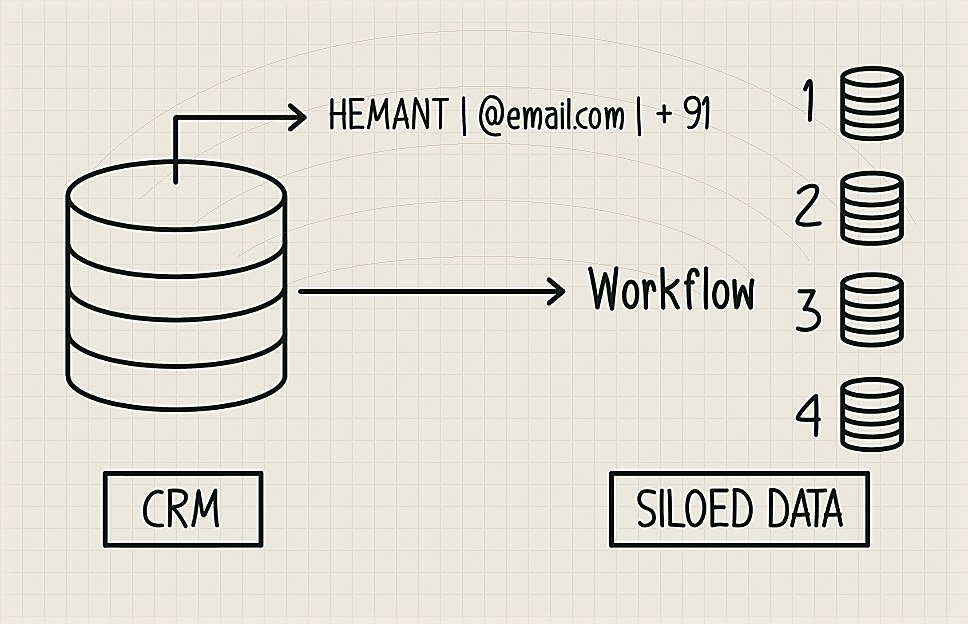
20–30 years ago as things started to get digitised, those who converted pen and paper knowledge bases to digital had a lock-in on what happens next with that data. When you break down these SORs, they are essentially a bunch of structured data-entries that may contain something akin to the below figure — a name, an email, some details about your background, what you like/dislike, and so on. On top of that, people have created workflows & automation tools. This has led to a bunch of siloed data about you spread across different tools — email, CRM, automation tools, communication platforms, etc. AI is now great at picking up these disparate structured & unstructured information and making sense of it. This is basically the “Gmail search” moment of the enterprise service bus — why do we need to design folders and processes on top of our emails when gmail search is able to surface the right results no matter how they are tagged/filed? Throw everything into a pile — no need to maintain a CRM of any kind? So that’s one big change that’s afoot. Second is around workflows built on top of these data stores, connecting them, making sense of them, doing bespoke tasks with them. All that needed a lot of software to be built in the past. That’s the second big change afoot.
When software was hard to build, human workflows adjusted to software interfaces
When software is easy to build, workflows will adjust to human behaviours
These two changes are going to redefine several large categories of softwares and the changes could first be in the architecture of these softwares — e.g. both back- and front-ends could look quite different — as well as far reaching at the organisational level with several functional teams no longer needing to exist or merging into each other as data silos go away.
2. 10 step → zero-step processes
This is somewhat related to the point I made above but still something that could be an investment strategy on its own. We are a lazy species. AI can now — across coding, writing/art, basic workflows like sending email campaigns — take days of work and do it in minutes. However, most things we do as humans are multi-step and the more steps that are needed to complete a task, the better it fits into the bottom red-blue edges of the “complexity / specificity” framework described earlier.
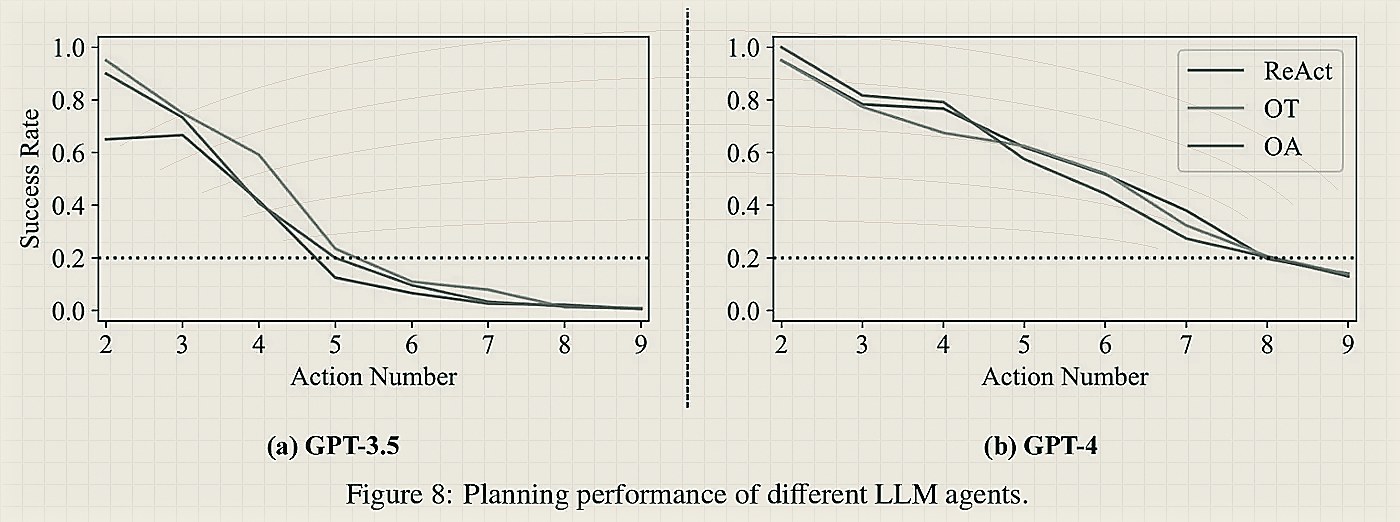
The above graph tracks success rates across 3 agentic frameworks — ReAct, OpenAI tools (OT) & OpenAI Assistant (OA) — used with GPT-3.5 & GPT-4. GPT-4 does better than GPT-3.5 and future reasoning agents might do better, but overall we are likely going to stay below <50% accuracy for anything around a 10-step process for the foreseeable future. Imagine trying to book a flight ticket via an AI agent — something simple that is at least a 10 step process today — and instead of an economy class, get booked into a far more expensive business class seat? Or worse, booked to a different city? That’s what a 1% error rate could do to you. So the 10-zero step process improvement is hard and valuable which makes it a pretty rich area of exploration for startups. It is also a defensible area — as the “5–10 step processes” get absorbed by LLMs, the world of 100-step processes is wide open and that’s where a majority of the human processes are, and that’s where the opportunity is.
3. What would AGI do (so you don’t have to)?
The final framework is more of an anti-pattern. It isn’t enough to think about what businesses AGI will make redundant when it arrives 5–10yrs later. On the path to AGI, the models themselves will start to take away a lot of the opportunity that feels approachable or necessary today. The graphic art that LLM generates is not exactly to your specs, or relevant to your industry? It’ll likely meet 99% of the needs for 99% of the people soon enough. Building a specific, opinionated approach to vector embedding stores, or LLM-ops? Watch out — the underlying LLM architecture may obsolete your category or may change itself making your solution irrelevant.

So, the final framing I’d leave you with are what I call the “rug hole opportunities” vs the “shrinking whitespace” opportunities. Rug hole opportunities are deep little insights on how behaviors are shifting today but will, over time, become default consumer behaviors. Like putting your fingers into a rug and ripping it open to make more room. Perplexity.ai is a good example of a rug-hole that will eventually expand to cover how the world of consumer search would operate no matter what technology it takes to get us there.
Shrinking whitespace opportunities come in many shapes and sizes — sometimes they are the 10th AI-enabled automation tool or co-pilot, or they are so beholden to LLM architectures that minor changes in underlying infra can force them to re-think their product & GTM. They look like open opportunities but are often surrounded by adjacencies that will erode the surface area available to you over time. If you find yourself in such a space where you feel the walls narrowing, pivot!
Sometimes shrinking whitespace opportunities can also be rug-holes in the near-term. For example, building the best scribing tool for medical use cases may eventually become a commodity, but companies could use the limited time available to land-grab their way into consumer/enterprise medical data-sets to eventually build what may be very defensible — a personal AI-doctor. The hard part is that many shrinking-whitespace opportunities feel like rug-hole opportunities so my recommendation is for founders to be extra vigilant and agile, and constantly iterate towards “death proofing” their businesses.
If you’ve read this far but haven’t yet read the precursor to this piece, I’d recommend it here. As expected, 2024 was a wild ride, and 2025 might be another. In the eternal words of Garrison Keillor, “Be well, do good work, and keep in touch”.
No comments yet.