
Guest Author: Meenal Nalwaya @ Reka-AI, ex-Meta AI (x, LI) w/ Hemant Mohapatra (x)
Robotics today feels stuck in a fascinating yet frustrating phase — a “gesture data” loop. Picture this: you grab a cup by the handle or pick it up from the top. It’s second nature for you. But robots? They need explicit instructions for even these seemingly simple actions. Why? Because robots aren’t equipped with physical intelligence — the ability to reason, adapt, and act in dynamic, unpredictable environments. Can robots transcend this limitation? And if they can, how do we scale them to truly match human dexterity and reasoning?
Modern robotics combines advanced AI techniques to give machines perception, decision-making, and control capabilities. Several architectures and learning approaches drive state-of-the-art / SOTA robots today.
We thought it might be fun to first give you a rather layperson’s view of what the SOTA approaches look like before we discuss where this category may be headed & the opportunities ahead of us:
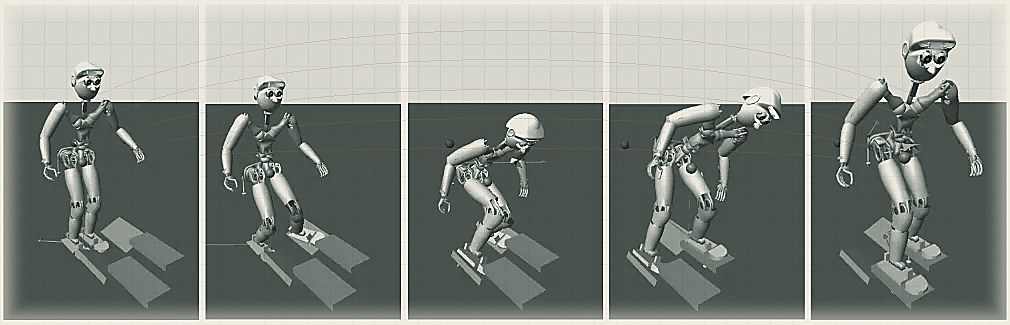
1. Reinforcement Learning (RL) — Robots can learn through trial and error by optimizing behavior for long-term rewards. In model-free RL, a policy is learned directly from interactions (no prior dynamics model). This has enabled robots to learn skills like grasping or locomotion from scratch, by exploring many scenarios in simulation or real life. Deep RL combines neural networks for perception with RL’s trial-and-error training, allowing end-to-end learning from sensors to motor commands. For example, deep RL was used to train a humanoid to walk over varied terrain by maximizing forward progress, using a transformer policy that observes sensor history and outputs joint actions. Such methods can yield impressive behaviors that classical control struggled with, like a bipedal robot adapting its gait to uneven ground. However, pure RL often requires huge data and many trials, making direct real-world training difficult. Sparse rewards and safety constraints are challenges, prompting techniques like hierarchical RL (decomposing tasks into sub-goals) to improve learning efficiency

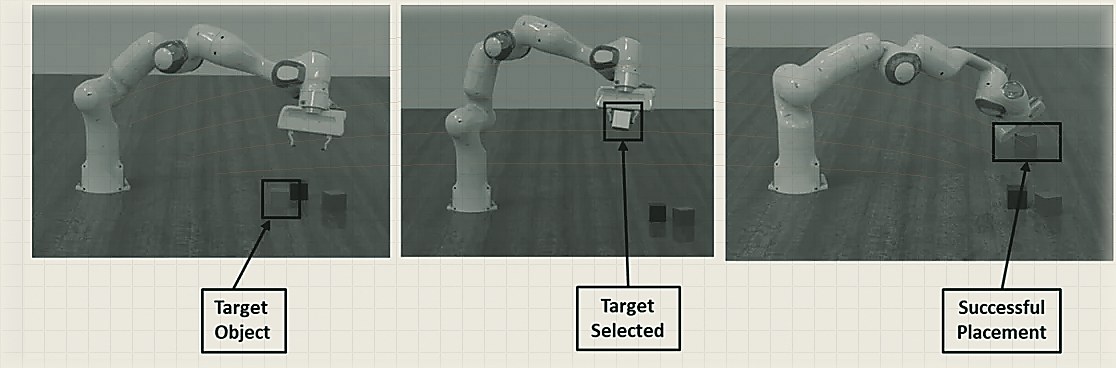
2. Imitation Learning (IL) — Instead of learning from scratch, robots can learn by mimicking expert demonstrations. In IL, an expert (human or another controller) provides state-action examples, which the robot uses to learn a policy. This focuses exploration and speeds up learning. Two common IL approaches are Behavior Cloning (BC) and Inverse Reinforcement Learning (IRL). Behavior cloning directly trains a neural network to map observations to actions by matching the expert’s trajectories. The limitation is that errors compound if the robot encounters states not in the demos. Inverse reinforcement learning addresses this by inferring the underlying reward function that the expert is optimizing. By learning why an expert acted as they did, IRL-trained agents can generalize better to new states or environments. More recently, Generative Adversarial Imitation Learning (GAIL) has been used, where a generator (robot policy) tries to imitate expert behavior and a discriminator ensures the generated behavior is indistinguishable from expert demonstrations. In practice, IL is often combined with RL (e.g. using demonstrations to warm-start an RL policy) to get the best of both — IL gives a strong initial policy and RL further fine-tunes it for higher performance.
3. Model-Based Control and Planning — Traditional robotics heavily uses model-based approaches: the robot’s kinematics and dynamics are modeled mathematically, and planners or controllers leverage these models to decide actions. For instance, model-predictive control (MPC) plans a sequence of forces/torques over a short horizon by optimizing an objective (like staying balanced or following a path) given the physics model. Such optimization-based strategies have enabled highly dynamic maneuvers while respecting physical constraints. A famous example is Boston Dynamics’ Atlas humanoid performing backflips and jumps — the control uses precise models of the robot’s dynamics and optimization to execute these feats. The advantage of model-based methods is reliability and safety: you can ensure the robot won’t violate joint limits or fall, as the planner “foresees” outcomes via the model. However, creating accurate models for complex robots and environments is hard — unknown friction, contact dynamics, or wear-and-tear can render models inaccurate. This is where model-based RL comes in: robots learn an approximate model of their environment (or their own dynamics) and then plan with that model. By updating the model from real data, the robot can adapt to changes.
4. Neural Network Architectures for Perception, Planning, and Control — Deep neural networks are now ubiquitous in robotics, handling everything from sensor processing to action outputs.
- Perception: Convolutional Neural Networks (CNNs) and their successors (e.g. Vision Transformers) allow robots to interpret high-dimensional sensory data. Robots use CNNs for object detection, scene segmentation, and depth estimation to understand their surroundings. For instance, Tesla’s Optimus uses camera-based vision similar to Tesla’s self-driving cars, with neural nets to detect objects and obstacles, effectively “mapping” its environment in 3D. Modern robots also fuse modalities — multi-modal perception networks take in vision, LIDAR, and even touch or audio. Integrating vision and touch can improve understanding of object grip or slips. This sensor fusion through neural networks helps a robot accurately estimate states like an object’s pose or the robot’s own location. In humanoids, perception nets feed into higher-level planners to enable behaviors like recognizing a spilled drink and locating a sponge to clean it.
- Planning/Decision: Once the environment is perceived, the robot must decide what to do. Classical planning algorithms (search, graph-based planning, etc.) are now often augmented or replaced by neural network-based planners. Recurrent neural networks (RNN/LSTM) have been used to handle temporal sequences of observations for decision-making — e.g. an LSTM controller that observes past states can learn when to lift a foot during walking.
- Actuation/Control: The final step is commanding motors. This can be done by low-level controllers (PID loops, etc.), but increasingly neural nets are used to learn the mapping from desired motions to joint torques. For instance, a deep policy might output joint torques directly to balance a robot, or outputs high-level joint targets that a secondary controller executes. End-to-end approaches literally go from sensor input (camera images, joint encoders) to motor currents with one neural network.
In summary, state-of-the-art humanoid robotics draws on reinforcement learning for acquiring complex behaviors, imitation learning for leveraging human skills, model-based control for stability and efficiency, and deep neural networks throughout the perception-to-action loop. A key research aim is to integrate these components seamlessly — e.g. an end-to-end system where a vision Transformer perceives the scene, an RL-trained policy network decides the action, and a learned controller executes the motion. This fusion is enabling robots to perform ever more complex tasks, though as we’ll discuss later, challenges like generalization and safety remain.
The Paradox: AI Beats Chess, But Fails at Dishwashers
Yann LeCun highlights a paradox: AI excels at language, abstract tasks like playing chess, and even complex surgeries, but fails miserably at basic physical reasoning like folding laundry or managing households. Why? Because reasoning about physical interactions and applying abstract skills to dynamic environments are far harder challenges. The human brain — even that of a four-year-old — has been pre-trained for thousands of hours in spatial and physical reasoning. A four-year-old who has been awake for 16,000 hours in his or her life, has about 10 to 15 exabytes of information that has reached their visual cortex. Robots, by contrast, start at zero and operate in brittle, rule-driven systems.
This brings us to a crucial insight highlighted by Rich Sutton’s influential piece, “The Bitter Lesson”. Sutton argues that historically, AI progress has come not from hand-crafting specialized solutions or meticulously engineered domain-specific intelligence, but from simply leveraging more compute and generalized learning architectures. Robotics today faces a similar crossroads: should we painstakingly build specialized models and controllers for every task and scenario, or should we follow the trajectory suggested by Sutton, investing in general-purpose architectures that scale naturally with compute power and data? While specialized methods can yield immediate, impressive results — like Boston Dynamics’ Atlas performing acrobatic maneuvers — they often hit ceilings due to brittleness in unseen scenarios. In contrast, general-purpose compute-driven methods (e.g., foundation models) offer broader adaptability, at the expense of initial efficiency or immediate performance. This trade-off — specialization for immediate impact versus generalization for long-term scalability — will define much of robotics’ evolution in the coming decade.
How are startups tackling this challenge today?
The landscape of AI-driven robotics (especially humanoid robots) can be segmented along several axes. Skild AI is developing the “brain” for robots to see and think, while Figure focuses on fully embodied robots capable of seeing, and reasoning and speaking in natural language (using OpenAI-powered models but recently decided to build their own). Below we classify robotics companies and projects by technical approach, application domain, hardware capabilities, the scope of AI intelligence, and business model:
1. By Technical Approach:
LLM-Powered Robotics — A new wave of companies use Large Language Models or other foundation models as a core of the robot’s intelligence. These robots leverage the kind of AI behind ChatGPT to reason about tasks, understand instructions, and even generate code for robotics. For example, startups like Skild and Physical Intelligence (PI) are building a general “brain” for robots using foundation models, inspired by the success of LLMs. Such companies focus on massive datasets (text, images, demonstrations) to train a single model that can generalize across tasks. The hallmark of this approach is an AI system with broad knowledge and reasoning ability embedded into the robot, enabling high-level cognition (planning steps to accomplish an instruction, common-sense reasoning about the physical world, etc.). This is in contrast to traditional robotics AI which might be task-specific. LLM-powered robotics is embodied AI that tries to bring the generality of chatbots into physical machines.
Traditional Deep Learning Robotics — Many robotics companies use AI, but not necessarily large language models. Instead, they employ domain-specific deep learning and reinforcement learning. For instance, Covariant and RightHand Robotics apply deep learning for robotic picking in warehouses — their AI is tailored to vision and grasping tasks (narrow AI). This category includes any company using neural networks for perception (vision, speech) and RL or supervised learning for control, without an LLM. They might train convolutional networks for object recognition, or policies in simulation for locomotion. The technical emphasis is often on end-to-end learning for specific capabilities (like “pick up any object from a bin” or “navigate through a warehouse”) rather than general reasoning. These companies stand on the shoulders of deep learning breakthroughs but focus the AI on a defined problem space.
Classical and Model-Based Systems — Some robotics companies rely more on classical control and do not heavily use machine learning. Traditional industrial robot manufacturers (e.g. FANUC, Yaskawa) fall here — their robots follow precise programmed motions using control theory and simple sensors. These systems might have minimal AI, perhaps basic computer vision or none at all, and excel in structured environments with repetitive tasks. Even among humanoids, early prototypes often used hard-coded behaviors or teleoperation rather than autonomy. Companies like Boston Dynamics historically achieved impressive results through physics-based simulations and optimization (model-based control) rather than learned neural policies. The advantage of this approach is predictability and safety — every action is well-understood. The downside is limited flexibility; a classical system can’t easily learn a new task without explicit re-programming. That’s why even incumbents are now adding AI modules, but it’s useful to segment those who lean heavily on classical robotics versus those that are “AI-native.”
2. By Application Domain:
Industrial and Commercial Robots — These are robots intended for factories, warehouses, and other industrial settings. Examples include robotic arms for assembly, mobile robots for hauling goods, or humanoids designed to perform labor in manufacturing. Tesla’s Optimus and Figure AI’s humanoid are aimed at industrial and commercial tasks (like moving packages, working on assembly lines) to address labor shortages or do dangerous work. The AI in this domain often focuses on reliability, precision, and integration with existing workflows. Industrial robots may operate in semi-structured environments (a factory is organized, but a general-purpose humanoid there still needs to handle variability). Thus, companies segmenting here emphasize safety and consistent performance, perhaps at the cost of some versatility initially.
Personal and Service Robots — This domain includes robots meant to interact with everyday people in homes, offices, hospitals, etc. Humanoid examples would be domestic helpers, eldercare robots, or hospitality robots. While full humanoid home assistants are still rare, prototypes exist. These robots need AI for natural interaction (speech and vision to recognize people or objects) and the ability to handle a wide variety of daily tasks (fetching items, cleaning, making simple meals). The application pushes toward generalist AI because home tasks are so diverse. Sanctuary AI, for example, envisions general-purpose humanoids that could work in retail or offices one day, which means their AI must be flexible across many tasks and safe around humans. Personal robots also include things like Pepper or Nao (SoftBank Robotics) — small humanoids used for customer service or education. Those rely on speech recognition, scripted dialogue, and simple autonomous navigation. The key distinction is personal/service robots operate in unstructured human environments, driving the need for strong perception and social intelligence.
Research and Exploration Robots — Many humanoid robots are developed for research (e.g. by universities or consortiums) and for exploring extreme environments (space, disaster zones). Companies or organizations here (like NASA’s Robonaut or Toyota’s T-HR3 humanoid) build humanoids to test AI in complex scenarios. The application domain is not immediately commercial; instead, these robots serve as R&D platforms. They often try cutting-edge AI without the strict reliability requirements of a product. In segmentation terms, these research-focused robots push the envelope in autonomy and are a proving ground for AI techniques that will later trickle down to commercial uses. In summary, domain segmentation recognizes that a robot built for a controlled factory will be designed differently (and likely with narrower AI) than one for the home or for disaster sites, which need broad and robust intelligence.
3. By Hardware Capabilities:
Mobility — Robots vary from fixed installations to highly mobile platforms. Humanoids inherently are mobile (bipedal), but some have higher mobility focus than others. For example, Boston Dynamics’ Atlas is optimized for dynamic mobility (jumping, running), showcasing agility more than manipulation. In contrast, stationary humanoid upper-bodies (like some laboratory robot torsos) might have no mobility, focusing on dexterous arms and vision. Even among mobile robots, differences exist: bipedal vs. quadrupedal vs. wheeled. Mobility impacts the AI — legged locomotion is a tough control challenge requiring either advanced model-based control or learned policies (Atlas uses model-based optimization for acrobatics, while some startups are using RL for bipedal walking. Wheeled humanoids (like a humanoid torso on a mobile base) can rely on easier wheel control but sacrifice the human-like navigation of stairs. Degree of mobility (can it handle rough terrain or only flat floors?) is another sub-segment. Companies often differentiate by saying their humanoid can operate in human environments (implying navigating stairs, ramps, clutter), which is a selling point of strong mobility.
Dexterity — This refers to the robot’s ability to manipulate objects. Not all robots have human-level hands; some humanoids use simple grippers or mittens if their intended tasks don’t require fine finger control. For instance, early Tesla Optimus prototypes have relatively simple hands (with a few degrees of freedom) aimed at basic grasping, whereas a company like OpenAI (research) used a Shadow Hand (highly anthropomorphic with many joints) to solve a Rubik’s Cube. A robot’s dexterity segmentation might range from low dexterity (just lifting objects or using tools with minimal finger articulation) to high dexterity (delicate manipulation, using keys, threading needles, etc.). High-dexterity hardware demands advanced AI for fine motor control and tactile sensing. Sanctuary AI’s Phoenix humanoid is reported to have very dexterous hands, aiming to exceed human hand capabilities. In contrast, Agility Robotics’ Digit has no arms/hands in its base model (it just carries boxes against its torso), focusing solely on legged mobility.
Autonomy Level — Some robots operate fully autonomously, others are teleoperated or human-supervised. For example, Sanctuary initially used teleoperation (a human remote-control suit) to have the humanoid perform tasks while gathering data, with the goal of gradually handing over more autonomy to the AI. We can segment solutions by how much human is in the loop. Fully autonomous robots (e.g. a warehouse mobile robot that navigates by itself or a demo of Optimus picking items without live human control) require a complete AI stack for perception, planning, and action. Teleoperated robots are often used in startup phases or in complex environments — a human pilot controls the robot, perhaps with AI assistance for stabilization. This distinction affects the AI needed: teleop-focused robots might need great latency and control interfaces but less onboard intelligence, whereas full autonomy requires robust onboard decision-making. Most humanoid firms target high autonomy eventually, but it’s useful to note which are actually deploying robots with a human teleoperator (effectively using the robot as an avatar) versus those that have achieved significant autonomous operation. Autonomy also ties to power and compute — an autonomous robot carries powerful computers and runs on battery, needing efficient algorithms (for instance, running complex vision models on edge GPUs). So, hardware-wise, autonomy level is a segment impacting design (sensors, compute hardware) and AI complexity.
4. By AI “Intelligence” Scope — this is the most interesting segment:
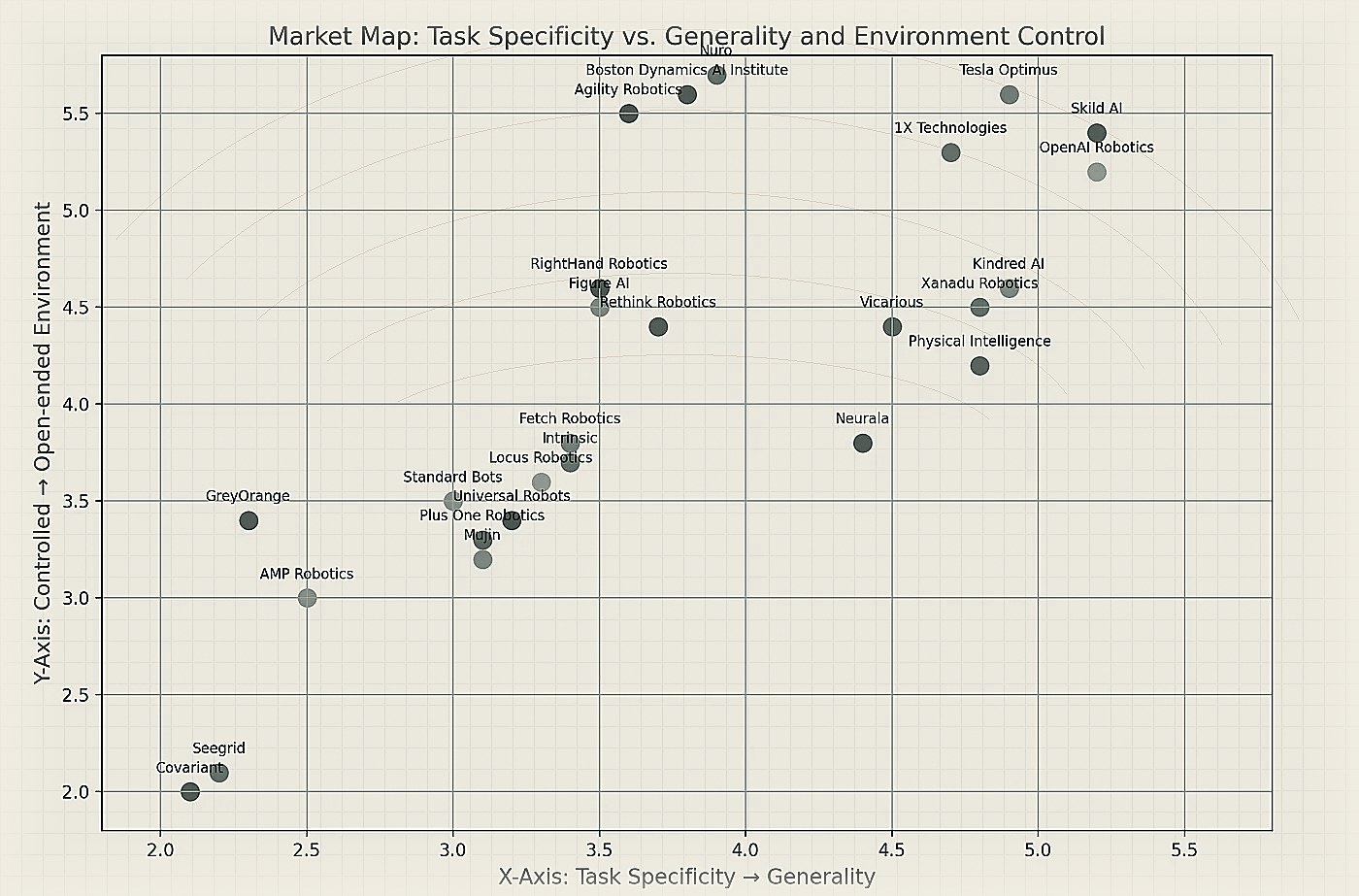
Narrow Task-Specific Intelligence — Many current robots are specialists. They are extremely good at a set of predefined tasks under certain conditions. For example, a robotic arm on an assembly line might only solder one type of joint, or a humanoid in a lab might be set up just to play chess on a life-sized board. The AI for these is narrow AI: models trained and tuned for the specific context. This could be a network trained only to pick up known objects, or an RL policy that only balances the robot for walking forward (but not handling any other instruction). Narrow AI robots often outperform humans in speed or precision at their single task (like pick-and-place 1000 parts/hour), but cannot do anything outside their programming. Many industrial deployments today are of this nature — replace a human in one repetitive job. However, scaling to new tasks means developing new models or code each time. Most current commercial robots (even ones using AI) fit here, from warehouse bots to surgical robots, each with a constrained domain of operation.
Generalist (Multi-Task) Intelligence — The holy grail for humanoids is a general-purpose helper that can perform many different tasks (like a human can). Companies like Figure AI, SKILD, and Sanctuary AI explicitly aim for general-purpose humanoid robots, which implies their AI is not just one skill but a framework to learn and execute a variety of skills. In practice, this might mean using foundation models or multi-modal learning so the robot can respond to novel instructions. For example, Physical Intelligence Pi’s model, called π0, is training on massive real world datasets aiming to train to a sufficient extent that it builds towards a general purpose model that is intelligent enough for real world use cases. This approach enables robots trained on Pi to perform a variety of tasks, such as sorting packages, stacking objects, and even intricate operations requiring fine dexterity. The expected result is robots that aren’t just good at individual tasks but capable of adapting across environments, much like humans. However, it still remains to be seen if teaching on large enough datasets can lead to a technical breakthrough in general intelligence or if we indeed need task specific training extending to closed and open ended environment.
In segmentation terms, only a few players currently have general AI ambitions in robotics — most notably those with strong AI research backing. These robots require large training corpora and often simulation on diverse tasks. The advantage if achieved is flexibility — such a robot could be repurposed via a software update or even on-the-fly learning, much like how an LLM can answer questions on many topics. The challenge is that generalist AI in robotics is very cutting-edge and not yet at human level. Nonetheless, it’s a key way to segment the market: are you building a one-trick robot or a platform that aims to eventually be an “Android” capable of many jobs? Businesses position themselves along this axis, with some proudly touting narrow expertise (to solve a problem really well), and others pitching a broader intelligence (to address labor gaps in multiple industries with one robot type).
Future Directions
Given these trends, where is the field heading?
- One clear direction is more generality and adaptability. In 5–10 years, we expect robots that can learn new tasks on the fly by observing one demonstration or even by reading an instruction manual. This is not far-fetched: if an LLM-based robot can parse a WikiHow article on “how to unclog a drain” and then attempt it, that would be a game-changer for general utility. Achieving that means improving multi-modal understanding and perhaps integrating retrieval (imagine a robot with access to the internet to pull up instructions when needed, combined with its embodiment).
- Another direction is collaborative robotics with humans — not just side by side, but fluid teamwork. Humanoids will need to predict human actions, coordinate handing objects, and align with human preferences. This might involve learning from watching humans directly (some research has “robot watches video of people doing tasks to learn affordances”). It will also require safety guarantees.
- We’ll also see specialization within generality — meaning, while the aim is a “do-anything” robot, likely we’ll have categories like robots that are generally great at home chores, others generally great at factory work, etc., with foundation models fine-tuned to those contexts. This is akin to how an LLM can be fine-tuned as a medical assistant versus a programming helper.
- Physical improvements are also in trajectory: battery tech, lightweight materials, and better actuators (possibly variable impedance actuators that can be both strong and gentle) will remove a lot of current limitations. As hardware improves, the AI can take more liberties because the robot will be physically capable of more dynamic or delicate maneuvers.
Remaining Challenges
Despite rapid progress, several core challenges remain:
- Robust Real-World Performance: Robots still struggle with the messy, unpredictable nature of the real world. Lighting changes, moving people, clutter, or atypical scenarios can degrade performance. We saw that no robot today can fold laundry as reliably as a human or do dishes. Dealing with deformable objects (cloth, cables, liquids) is still very hard for AI. While LLMs give knowledge, actually manipulating a limp cloth uses tactile feedback and intricate control that current policies can’t handle well. So, one challenge is mastering deformable object manipulation and other “unstructured” tasks. It may require new sensor tech (better touch sensors, etc.) and huge datasets of those tasks.
- Data Efficiency and Generalization: The current foundation models are trained on massive data, but what about something truly new? Humans can generalize from a few examples in the real world amazingly well. Robots might have read about an action, but when facing a totally novel combination of circumstances, can they adapt? We need robots to be lifelong learners, not just model executors. Techniques like on-device fine-tuning, or continual learning algorithms that don’t forget old skills when new ones are learned (avoiding catastrophic forgetting), are active research areas. Ensuring that a generalist robot that learns a new skill doesn’t somehow ruin its performance on others is a challenge. Interestingly, virtual reality (VR) has emerged as a key enabler in robotic training. VR allows developers to simulate real-world conditions in controlled environments, accelerating learning and reducing costs. Startups like IHMC Robotics have demonstrated humanoid robots sparring in boxing matches or playing ping-pong with humans, using VR to create low-latency, highly adaptive training scenarios.
- Safety and Ethics: As robots become more autonomous and LLM-enabled, we need to ensure they act safely and in alignment with human values. This involves technical safety (not knocking over people, avoiding hazardous mistakes) and ethical decision-making. For example, if an LLM-driven robot is asked to do something that could harm property or privacy, it should refuse or ask for confirmation (just like ChatGPT has refusal for harmful requests). Work on AI alignment in robotics is nascent — it may involve human feedback training, explicit ethical rule integration, and rigorous testing in simulations of edge cases (like, what does the robot do in a dilemma situation). Regulations might also require explainability — why did the robot take a certain action? LLMs can potentially explain their reasoning (“I did this because…”) but the fidelity of such explanations is not guaranteed. Developing robots that people trust will be as much a policy and UX challenge as a technical one.
- Hardware-Software Co-Design: Many AI researchers treat the robot as given, and many roboticists treat the AI as a black box input. Closer integration is needed. For instance, if we design a hand specifically to be easy for an AI to control (maybe with sensors that directly feed a learned policy well), that’s co-design. Or designing models that consider energy efficiency if the hardware is battery-limited. Today’s large models might drain a robot’s battery just from computation. So either hardware needs better computing efficiency (FPGAs, neural chips) or models need to get thriftier. There’s a challenge to balance the two — perhaps specialized hardware for running transformers quickly on robots will be a field of innovation (NVIDIA is certainly looking at this). Tesla’s approach of building their own chip (Dojo) to train and possibly run models is one angle.
- Benchmarking and Evaluation: We need better benchmarks that truly gauge a robot’s general intelligence and usefulness. It’s relatively easy to measure success on a narrow task (success/failure, time to complete, etc.), but how to measure a generalist? There are some efforts like the “Real Robot Challenge” (annual contests where teams have to make a robot do a set of tasks it wasn’t completely prepped for). We might see something like a Turing Test for robots — e.g., can a robot work a day in a retail store unnoticed as a robot? Developing standardized tests — perhaps a list of household chores and measuring what fraction a robot can do in an unscripted home — would guide research. Alongside this, simulation benchmarks need to correlate with real-world performance better so we can trust sim results.
- Collaboration and Interoperability: If many companies create their own “robot brains,” how will they work together, or will they? Unlike personal computers where standards allowed interoperability, robots might become walled gardens. ROS was a great standard in research; whether something analogous emerges for cognitive models is unclear. A challenge is to avoid fragmentation that could slow overall progress.
Despite these challenges, the momentum in AI-driven humanoid robotics is immense. We’re at an inflection point. The combination of huge model advances and improved hardware has created a feeling that the long-standing dream of helpful humanoid robots is within reach. The next wave of robotics will be defined by its ability to handle nuance, unpredictability, and failure. The next few years will likely bring the first real deployments of humanoids in jobs, and academia will continue to break barriers such as solving previously impossible tasks or greatly reducing training time via clever algorithms.
The journey is complex, but the progress thus far paints an exciting picture of the robots of the future: ones that can see, think, learn, and communicate in ways more akin to ourselves, all thanks to the cutting-edge AI now being imbued in their silicon brains. Robotics doesn’t just need evolution; it needs a revolution.
No comments yet.